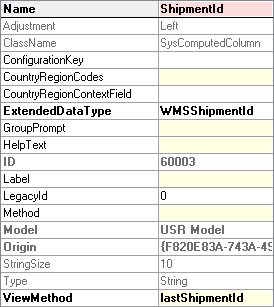
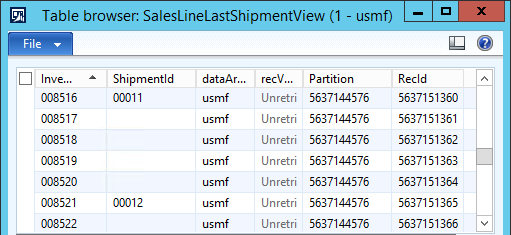
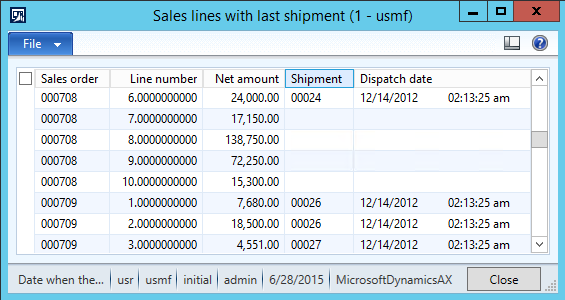
You sometimes need to connect from Dynamics AX to another database and read or write data there. The usual approach uses OdbcConnection class, as described on MSDN in How to: Connect to an External Database from X++ Code [AX 2012]. Although it definitely is a possible solution (I used it already in AX 3.0), it has so many problems that I almost never use it these days.
My intention is to show one of possible alternatives that solves many of these issues. Although the core idea can be used in AX from version 4.0, this blog post uses AX 2012 and depends on several features that don’t exist in older version.
First of all, look at how you’re supposed to construct the query for OdbcConnection:
sql = "SELECT * FROM MYTABLE WHERE FIELD = "
+ criteria
+ " ORDER BY FIELD1, FIELD2 ASC ;";and how to get results:
print resultSet.getString(1);
print resultSet.getString(3);
(This is taken from the sample code on MSDN.)
You have to define the query as a simple string, therefore you have to write SQL code by yourself, you won’t get any IntelliSense, compile-type control or anything like that. You have to execute your SQL against the target database to find errors such as misspelled field names.
You also depend on column indexes when accessing data, which becomes cumbersome very quickly and it’s easy to break. For example, notice that the query above selects all fields. What will happen if I add another field, e.g. the query starts returning ANewField, Field1 and Field2 instead of Field1 and Field2? Column indexes now refers to different fields and it again won’t be found until actually running the code.
It’s simply unpleasant for development and horrible for maintenance.
Wouldn’t it be better if we could simply refer to field as if we do in normal X++ development, get compile-type control and so on? Good news – we can!
![Ssms_Table]()
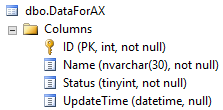
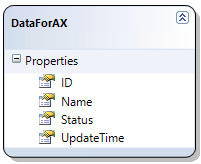
Before we actually start, let me show you the table that will simulate my external data. It has four fields: ID and Name that I’m going to import to AX, Status used for tracking what needs to be processed and UpdateTime storing the data and time of the update.
It can be created by the following script:
CREATE TABLE [DataForAX](
[ID] [int] IDENTITY(1,1) NOT NULL,
[Name] [nvarchar](30) NOT NULL,
[Status] [tinyint] NOT NULL,
[UpdateTime] [datetime] NULL,
CONSTRAINT [PK_DataForAX] PRIMARY KEY CLUSTERED
(
[ID] ASC
)
)You can also put some test data there:
INSERT INTO DataForAX
VALUES (N'Croup', 0, null),
(N'Vandemar', 0, null)
Note that it’s important for the table to have a primary key, otherwise we wouldn’t be able to update the data.
![AxObjects]()
Let’s also prepare some objects in AX. We’ll need a table storing the data and because the Status field is an integer representing various states, we can very naturally model it as an X++ enum.
Status field values:
- 0 = Ready
- 1 = Imported
- 2 = Failed
Now start Visual Studio, because most of our work will happen there. Create a new C# class library, add it to AOT and drag the table and the enum from Application Explorer to your project. We’ll need them later.
Open Server Explorer (View > Server Explorer) and create a connection to your database. I’m using a SQL Server database on the current machine, but you can use ODBC, connect to remote servers or anything you need.
![ServerExplorerAddConnection]()
![ChooseDataSource]()
![AddConnection]()
Now you should see your tables directly in Server Explorer in Visual Studio:
![ServerExplorerTable]()
Right-click your project in Solution Explorer, choose Add > New Item… and find LINQ to SQL Classes. Set the name (TestDB) and click Add.
![AddLinqClass]()
A database diagram will be added to your project and its design surface will open. Drag the table from Server Explorer to the design surface.
![DesignSurface]()
It will not only render the table in the designer, it will also generate a class representing the table (and a few other things needed for LINQ to SQL). If you want, you can open TestDB.designer.cs and verify that there is a class for DataForAX table:
public partial class DataForAX : INotifyPropertyChanging, INotifyPropertyChanged
{
private int _ID;
private string _Name;
private byte _Status;
private System.Nullable _UpdateTime;
…
}It’s a more advanced topic, but notice that it’s a partial class. It allows you to extend the class without meddling with code generated by the designer. Extending the class is useful in many scenarios, but we don’t need it today.
There is one thing we should change, though – the type of the Status field is byte while would like to use our enum from AX. Go to the designer, open properties of the Status field and type the name of the enum (ExtRecordStatus) into the Type field.
![StatusFieldProperties]()
![MapToEnum]()
It might look as nothing special, but I think it’s pretty cool. We’re mapping a field from an external database to an X++ enum (albeit through a proxy) and we’ll be able to use in LINQ queries, when assigning values to the field and so on.
Now add a new class to your project, call it Data, for example, make it public and add the Import() method as shown below:
public class Data
{
public void Import()
{
TestDBDataContext db = new TestDBDataContext();
var query = from d in db.DataForAXes
where d.Status == ExtRecordStatus.Ready
select d;
foreach (DataForAX record in query)
{
ExtTable axTable = new ExtTable()
{
ID = record.ID,
Name = record.Name
};
if (axTable.ValidateWrite())
{
axTable.Insert();
record.Status = ExtRecordStatus.Imported;
}
else
{
record.Status = ExtRecordStatus.Failed;
}
record.UpdateTime = DateTime.UtcNow;
}
db.SubmitChanges();
}
}Let me explain it a little bit. Firstly we create a data context:
TestDBDataContext db = new TestDBDataContext();
It’s a class that defines where to connect, track changes and so on. In real implementations, I usually store DB server and DB name in AX database, create a connection string from them (with the help of a connection string builder) and pass the connection string to data context’s constructor.
Then we create the LINQ query.
var query = from d in db.DataForAXes
where d.Status == ExtRecordStatus.Ready
select d;This simple example can’t show the full power of LINQ, but it’s obvious that we’re not building SQL by ourselves; we use strongly-typed objects instead. Notice also how we filter the data by the X++ enum.
The foreach loop fetches data from database and fill it to an instance of DataForAX class. Later we simply access fields by name – nothing like resultSet.getString(3) anymore.
This code:
ExtTable axTable = new ExtTable()
{
ID = record.ID,
Name = record.Name
};
if (axTable.ValidateWrite())
{
axTable.Insert();
}sets data to an AX table buffer (ExtTable is the table we created in AX at the very beginning) and calls its validateWrite() and insert() methods as usual. I typically pass records back into AX and process them there, but inserting them to AX database from here works equally well.
Then the code changes values of Status and UpdateTime fields. Finally db.SubmitChanges() writes changed data to the external database. We could also insert or delete records in the external database if needed.
That completes our library; the remaining step is calling it from AX. Open project properties and choose where to deploy the library. We’ll run it from a job for demonstration, therefore we have to deploy it to the client.
![DeployToClient]()
Rebuild the project and restart your AX client, if it was running.
Create a job in AX and call the Import() method from there:
try
{
new ExtSystem.Data().Import();
}
catch (Exception::CLRError)
{
throw error(AifUtil::getClrErrorMessage());
}That’s all what we need to do here, because reading the data, inserting them to AX database and updating the external database is already handled by the .NET library.
The whole application has just a few lines of code, doesn’t contain any strings with SQL commands, it doesn’t depend on the order of columns, the compiler checks whether we use data types correctly and so on.
It may require to learn a few new things, but I strongly believe that AX developers should look more at how things are done these days instead of sticking to old ways and low-level APIs such as the OdbcConnection class. Many great frameworks and language features waits for you to use them to increase your productivity and develop things hardly achievable in X++ – and AX 2012 made it easier than ever. It’s would be a pity not to benefit from all the progress done in recent years.
I couldn’t really discuss LINQ or the database designer while keeping a sensible length of this post. Fortunately you’ll find a plenty of resources about these things. LINQ to SQL also isn’t the only way – maybe ADO.NET would be more suitable for your particular project. Nevertheless I hope I managed to show you how to use these frameworks from AX – and that it’s not difficult at all.